
Discussion at EtherPad regarding UI improvement project
MoinMoin Wiki UI Improvements
Improving Global history view (./)
- be careful with license of icons / code / css you re-use
Icons could be from Tango icons library or FamFamFam Icons, they both give freedom to use their icons. custom icon will be added as background-image for css style for save/trash/rename and others actions. - there is no edit action
- delete is different from 1.9 and rather "trash" nowadays
Grouping will be done in the template file itself. Like 20 results have to be displayed, then i will check for the date value of each result. if it isn't same as previous one (as the result will be sorted on the basis of timestamp) then i will start a new divison and hence all the results will be shown grouped. I suggest you rather do this in python code. As you can easily see in 1.9, that code can be rather complex and python is more suitable than jinja2 then. Both Approaches: Currently history object is sent to the template and i can easily do the grouping there itself without changing much to python code. While doing this in python code itself, the history object(which is being sent) should have different such grouped history object and this grouped object will be iterated for results.
The algo for grouping will be pretty much same in both the cases, one has to be written in jinja2 and other in python itself.
But while doing grouping in python, for displaying the results the order will increase. 1)In python function itself: One loop to perform grouping in python (Groups: group1, group2...)
2) In template file: Nested loop.One to itereate over Groups and one to iterate over Please keep also in mind that templates can be used from 3rdparty for styling only. So if you move too much python code into the templates this can become impossible. Also it can become a mess because it is then nothing else as the opposite we have in 1.x, where all template stuff was python code.
Note: moin 1.9 RecentChanges does more than just grouping by day. It also aggregates multiple changes of same page into one entry. If the viewer has a bookmark set, it also makes sure only to show stuff he has not read already. Adding a filter option ---------------------- like filter on date basis (e.g. from 1/Jan/2010 to 10/Feb/2011 OR just Jan/2010 to Feb/2011 as done in Mediawiki), as currently in moin 1.9 it is for last 10, 20, 90 days, so in moin2 we can provide both of the options). -- Similar to bookmark functionality, will put condition on datetime attribute. Bookmark funtionality (./) -------------------------- A user should be able to set a time-bookmark (up to what time he has read everything displayed on RC), so he can later continue from there. (see moin 1.9) As the bookmark functionality is already implemented in moin2 (only at backend), i will just fetch the bookmark value in history function and will put a condition in the query for the rev_table.c.datetime attribute (have to check whether timestamp works) and the result upto bookmark will be shown.
Add filter option like just show the history of newly created items or the deleted ones or only the modified ones. implementation: Need to know that whether we could put condition on the query like fetch only those revision which are new item revision. Is there any attribure for rev_table exists, on which we could put condition for the query.
---Need suggestions. maybe first think about how often a user would want to see only history with created/deleted items. we didn't have that in 1.9 and it was never requested. so maybe this is not needed? May be we should move that idea to a admin view. It would be good to know which items were never changed after creation. Such stuff was called "AbandonedPages" in 1.9.
Paging will be done for each kind of query, there is option to set offset in the query by passing start and end parameter to the function. Issues with paging: As the output will be grouped day wise, suppose we fetched 20 results and result no. 19,10,21 belong to any date say 'x'.Then on our page for date 'x' only result no. 19 and 20 will ne shown and result 21 will be shown on the next page.
So i just wanted to assure that wouldn't it become confusing for the user as he may assume that on date 'x' only result no. 19 and 20 took place and wouldn't know about the 21st unless he reached to the next page.
if there are many edits of one item some days ago they should become paginated because if we don't do that it will need until it becomes edited at the next day again all that space.
In 1.x I have some wikis which get forecast images uploaded. For the last campaign that was 400 images per day. Without cleaning regulary RC becomes unreadable. Currently we are having changes of single item in grouped form, so in pagination, if we retrieve say 20 results at a time and lets assume that those 20 results belong to that single item, then on a page only changes of that single item will be seen. So will doing something like this desired? I think one should not show less than 1 day and only pagebreak at day boundaries.
Do you suggest to use that start and end parameters implemented in storage/backends for the history retrieval ? You can use whatever you like, but it might be not sufficient. If i use that then what you said above wont be achievable? It wouldn't be very helpful at least. so apply the logic in the function itself ? but it would make to do some unnecessary fetching ? So how should i limit the results ? For the page 1 it is fine, but for the page 2 i have to start from a offset, so do you want to keep offset a date ? well, obviously this needs some thinking. :) you have to do the day grouping in your code. the history is an iterator, so just use it like that and don't care about what it does internally.
the current implementation might change due to whoosh, btw, so just use the api, not so much the internals below the api. So how about limiting the number of days to show on a single page ? say 7 ?
I guess you need 2 limits and use whatever is reached first. days and entries. a single days with 400 entries is enough for a page, but you don't want to show just 1 day with 1 entry, but rather 7 then (for example). Or have a goal of N entries and break at the nearest day boundary.yes i understood this logic,by entries you mean items or revisons of items? changes/revisions. So for the offset of next page i will pass the date from where to start? That only works for rc, not for generic paging code. try to create something generic. how about storing it(offset) in a cookie ? we will have url like /?page=2 by this we can have some permanent linking ? i don't think you need a cookie, you can just give it to the template and use it in links. the questions is rather WHAT you want to use. using integers will look good, but how do i get what does that integer means ? using dates will make it easier or timestamp ? what say
I guess you'll just use some "offset" and "count" param and put there whatever is needed for that view/controller to render the next page. offset can be a date for rc or an integer for history. count can be n days [or days:entries] (rc) or n entries (history). very well, i will see what fits right when i start some work on it.
start with a generic paging thing. you can use item revision history, for example.
Issues:
- How to find out the offset for previous page ?
if you have a long page first you can split it in pages and know then everything. There is a limitation because of changes meanwhile. if you process it always from the beginning you have also this problem but from the other direction. there the entries can be confusing because you may see something in two of the paginated pages. I prefer the first, because it matches the time when I clicked RC.
How do i split them ?
As previous discussion already. if less content per days then 7 day split. if much content don't do more than 400 lines but don't split in a day. So if it is 450 or much more it is one page in pagination. yes i have tried something similar now, at the end of processing i know the offset for next page, but the below problem is still there ? how to fix this?. It fixes automaticly. you have then e.g. 90 days in a long table, you split that always and show only a selected part.lets take a example suppose in first page i have to select from changes 0-20, and in this 19th,20th and 21st change belong to same item, but 21st lie in a different date and thus skipped, so for next page i have to start from 21, so again here that 21st change will appear, which got suppressed earlier ?
not sure where it is confusing. if you now show without pagination you see only recent changes, also changes where accumulated so that you can't have a change for something on the 20th and on the 21th. the 20th is surpressed. This can't change using pagination.
so if you start on the 21st then you just don't see the change on the item for 20th if it had a newer change day.okay you mean first accumulate themn and then do selection ? yes - otherwise it can go wrong.as in my code i do the aggregation of comments,revnos etc then go for day grouping, so i just wanted to be sure in the case where these earlier steps may go unused for some items, is this right to do ?
it is not clear to me "why unused"?go to the code link in chat. and in the same code from line 643 i am doing datewise grouping where i can put limit in no. of results. you mean you don't want to paginate grouped_history ? I thought you just use all of the code and paginate it afterwards before feeding the template.that could be easier and error free, you mean during filling grouped_history i check there or after filling it completely ? it depends a bit how fast that is. but if you can fill it completly and split it afterwards it is at the time where originally History was called. Otherwise the result can change.
that is similiar to search where also pagination is needed. if you search again for the second page the result can differ. okay so i will be doing pagination after forming that grouped_history list.
And one more issue, how to find the previous offset ? you can have it in a query param. thomas mentioned to use start and count. that sounds good, flexible for other stuff too.you mean for a page if start is 5 and count is 20, offset will be 5, right ? yes and for the next 5 + 20 + 1 and it will change in the query. you may be need an additional parameter because we don't know yet to handle if there are too much entries per day. first let me be clear what will be start and count in url ? i thought stat will be offset but count ? it is the amount to go forward. it can be lines of RC but then you need a logic which figures when lines ends in a day. that it can adjust it. So that in this case if it is 20 and that is in the middle of 21st it knows to do the whole 21st. And increase offset then.but again how will i get the start for the previous page ? if you iterate by a step size to something the iterator has it or not? i will iterate over results and start considering it when i crosses the offset and includes until i met the count.
you can have a tuple pair of start, realcount that must be calculatable because the amount can't change in that approach.
if it is an easy one example. only one edit per day of one new page. then the result is e.g. a step of 7 days. i am getting your point but here i dont know how much is the step size i.e in general in paging from offset we can calculate the previous link just by subtracting a defined number from the offset ? or having a function. but here the size is changing for per page so i can get offset for next page, but i still wonder reg offset for previous page, just consider this case and tell me. the space consuming parts are the amount of cs in a day section. you can count this amount and have a given limit to decide it becomes only one page in pagination or in total by an other limit how much cs are possible to get into one pagination page.
the function just returns using these parameters the calculated value. the function has to find which line of changeset fits best to a day and split there.yes getting your point OR i will see if can use some parent param for url for the previous link. sure you can store it in a query param. okay i guess now i can start working on it.thanks for helping me so far. you are welcome try to make a test with many entries so we know about how slow/fast this method is.will do. if you don't have seen we have a moin command create_item for cli. moin maint_create_item
and one moe help, whenever i do any small change in function moin get restarted and it kills lot of time, is there any solution for this ?
it did not kill time because it autoreloads your change otherwise you have to kill the server and to restart it.i mean as compared in php development, just write and save it and it comes on browser no waiting there, i was expecting something similar here, but anyways.
this is because of cgi.moin uses now internally wsgi since 1.9 completly. there you have not a new request doing a reload of the codebase. and if you are on a server you can decide to do whatever middleware you want. but the python server is now for moin a werkzeug wsgi server and has this limitiation and some much wanted features. i think the autoreload can be disabled. but then you have to restart the python builtin server. thanks for the info.
does php also offer a builtin server, i have not much experience with it, stopped some years ago? no it works with apache. ok, for debugging of code it is easier to be independent from apache. because with it you can do logging but not stepping through codelines. moin runs as wsgi app on apache too. we had before 1.8 a lot of deployment code for different adaptors. at 1.8 we started to unify and in 1.9 it was completed. now maintanance and testing / bugfixing is easier because it is always internal only wsgi.i needed to display the value of intermediate variables, whenever i write print command, moin has to get re-started, otherwise no such issues.
we develop with the builtin desktop wiki usually and that is limited to what python offers. you have two choices now, disable autoreload and doing it manually (stop restart wikiserver process) or live with it as it is. Another solution may be is to use eclipse debugging. ii)During grouping for a item, i use to suppress the changes which occured in previous days, but as we move on to next page we are rejecting the revisions which falls under offset, so the item revisions which occured on previous days are shown here.
this will then resolved too. another reason for doing it that way. in the past 1.x wikis we could have had a extremly long list by uploading attachments for one page. you should take care that if we show subitems grouped in RC of an item, that this did not happen again. There it makes sense to paginate the results.
Another question we have to discuss: Should we show the dependency of an subitem to an item in RC? Not in first version, maybe never. Implementation plan for paging the history results (./) ======================================================= First there needs to be a plan for this, before starting to trying to implement "SOMETHING". And if you invest time in paging functionality, please do it in a reusable way, we will definitely need this at multiple other places also (history, search results, user list, maybe page list, ...). Global index should be categorised alphabetically (./) ====================================================== alphabetically -------------- Like rather than just showing the flat index we can have all items grouped alphabetically. Have to modify the get_index function (creating a new function will be a good idea), changing the sub_item_re may work. But the wikis which are not in English language may react differently.(Dont know whether using unicode for the alphabets to create the regular expression may fix this problem).
---Need suggestions. i don't think regex for get_index is helpful. you get full index and then do the grouping. Current implemantation of gobal index as of http://www.moinmo.in/AkashSinha/Gsoc2011Diary/2011-07-01 shows something similiar nautilus compact view. It misses indication for items subitems. subitems may be should link to the items index view showing their subitems. The items subitems index needs back navigation to the calling global index. As currently when the link of item is clicked it shows the item, so maybe we can show the subitems here, but this thing looks better when we have directory-files kind of storage. We don't have directory like storage. May be a [+] before the item links to the items index of subitems. OR simply we can show all the items here in gloabl index, items along with the subitems, something like this http://moinmo.in/AkashSinha/Gsoc2011Diary/2011-07-01?action=AttachFile&do=get&target=allindex.png not really good it can be a huge list and it is disconnected to the items index for subitems. filter implementation for major mimetype as checkbockes default enabled. This makes the transition from old moins user easier if they are only interested in text items. (This was the behaviuor of TitleIndex in the past) Do we want to have additional something similiar to the list view of nautilus? Do we want to have additional something similiar to the icon view of nautilus? Some ideas/questions:
{kind=link}
- How can we cheap create the preview images?
- for some types svg can be used, so we don't need different sizes
- needs storing in cache
- needs may be a cli script which runs regulary on the server
- we can set placeholder icons until the preview is available
i) Merging the functionality of index2 and index First, will replicate the file upload functionality. All the new uploaded files will be kept in a different section on page, such that they will be seen as newly added items (until the page reloads).
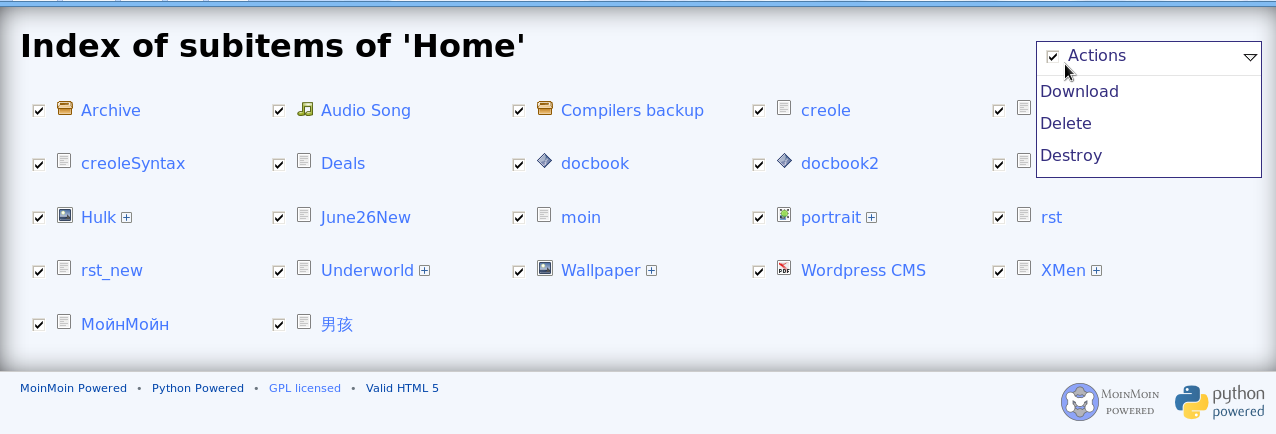
ii) We can put some collective action on page for the indexes, the view could be something like this http://www.moinmo.in/AkashSinha/Gsoc2011Diary/2011-07-17?action=AttachFile&do=get&target=multi-download.png. We could have Download, Delete and Destroy actions there. Move ? For multiple download of files we could have something this kind of feature http://www.search4campus.com/download.html For multiple download there must be a selection by a filter. E.g. all images and then this selection have to be downloaded. For Delete/Destroy we could use ajax for that, when someone selects some items and trigger delete action, we will ask for a comment (common for all) and will call a "view" for delete function (similar to one which is called by +delete/item_name). This function will simply return the status via json and we can hide the deleted items from page after getting a success status and display error message on failure.
{kind=link}
We can modify the item-views on top for the items there in index, as currently when we do Copy, Rename it do these actions for the item itself whose index is being shown. Try to not confuse users. "Index" itself is a view, so it is in that "views bar" (views that are somehow related to current itemname). If you just redefine the semantics of the views bar, users might get confused about the scope of their actions. Merging the index (./) ====================== Initially we had 3 different index a) global_index: showed top level index b) index: showed index of an item c) index2: showed index of an item as well as had file upload/download feature. So as fo now, view of global_index and index has been modified and made consistent. global_index has some extra features like startswith a character filtering and contenttype filtering. And after removing the index2, we have the file upload functionality at index itself. Thus the code for global_index and index is almost similar and so they are duplicated at two places. and also we require the similar feature to be present at both the plces. So by merging the global_index and index i) we will get free from some lines of code ii) it will be easier to add-new/modify functionalities iii) And index views will become more consistent. And finally we will be having only 1 index and currently with the features like startswith filtering, contenttype filtering and file upload.
Showing inline diff
We could show somewhat similar to http://www.pmwiki.org/wiki/Cookbook/InlineDiff I have tried this code. import difflib def show_diff(seqm):
output = [] for opcode, a0, a1, b0, b1 in seqm.get_opcodes():
- if opcode == 'equal':
- output.append(seqm.a[a0:a1])
- elif opcode == 'insert':
- output.append("<ins>" + seqm.b[b0:b1] + "</ins>")
- elif opcode == 'delete':
- output.append("<del>" + seqm.a[a0:a1] + "</del>")
- elif opcode == 'replace':
- output.append("<repold>"+seqm.a[a0:a1]+"</repold><repnew>" + seqm.b[b0:b1] + "</repnew>")
- else:
- raise RuntimeError, "unexpected opcode"
return ''.join(output)
sm = difflib.SequenceMatcher(None, "I am Akash Sinha i know python ", "I am Sinha Akash ,well i can speak C fluent ") print show_diff(sm) Output: I am<ins> Sinha</ins> Akash <repold>Sinha</repold><repnew>,well</repnew> i <repold>know pytho</repold><repnew>ca</repnew>n <ins>speak C fluent </ins> I will add css styles for each different tags i.e. for ins,repold and others, to present them in a nice way.
---Need suggestions whether this output is desirable or not. additionally to current diff view maybe yes, but do not replace current view. we already did experiment with misc. diff views some years ago and found that each method has its pros and cons. Yes i have also put some thought in it at earlier stage, I talked reg this with ThomasWaldmann and we agreed on keeping both the diffs namely one small diff (above one) and one full diff (current one implemented in moin2)
Loading meta elements using ajax
.... and no need to go to the different view just to see the meta elements. Will call the current meta function at backend via ajax and create a new template file which will be having only meta elements and nothing like header and footer (as done currently for the page /+meta/<item>). i.o.w. you will just transfer the metadata as json. yes, switching between misc. item views without reloading the page is nice to have.
Improving the content editor area
Adding a help section at the top of content editor which will be loaded in demand as well as will be categorized manner,so will be helpful in guiding a user in modifying a document. The help will also be based on the template of the item i.e. different for mediawiki kind of item and for moin moin type of item. This image could be used as a reference like how this help menu will be shown. i.e. at top of editor box and will be opened when requested. http://web.iiit.ac.in/~akash.sinhaug08/moin/editor.png For the help section, will create the static html help files in backend and will load them dynamically on demand. There will be different html files for each kind of help item (eg. 1 for Moin type, 1 for Mediawiki type... like this) And each html file will have different sections like: Help for Headings,Help for Links, Help for Lists etc. (Refer above image for the clearer idea). delay this until end. i am not sure we want it like that.
{kind=link}
Adding a tree like view for indexes (subitems) (./) partly implemented by back links and [+] links
... on the index page of a item and also could provide the few more options out there. ... (add details about implementation plans) ... see other (second) index view with jquery.file-upload functionality.
Collecting tools / ideas
The main topic of this pad should be the moin2 ui soc project (random nice UI stuff found on the internet should be only added where needed/appropriate). Please, for each tool/URL, add a note about how this is related to sinha's project (see his project application). If it is unrelated, keep the stuff somewhere else. tree related to 6) Adding a tree like view fileTree: http://labs.abeautifulsite.net/projects/js/jquery/fileTree/demo/ jstree: http://www.jstree.com/ tables related to 1) Improving Global history view NEED: syntax for th http://www.datatables.net/ editors related to 5) Improving the content editor area: http://markitup.jaysalvat.com/home/ Ideas from http://www.problogdesign.com/resources/50-jquery-tools-for-awesome-websites/